So, here is a recap of a few things I have released since. And also, how is it leading to a substantial growth in my Rust knowledge.
Ksunami gets an official Docker image
In an attempt to make adoption easier, I setup ksunami-docker so that running
ksunami can be ever easier; in Docker, Kubernetes or wherever you
need. For example:
apiVersion: v1
kind: Pod
metadata:
name: ksunami
labels:
ecosystem: kafka
purpose: workload-generation
spec:
containers:
- name: ksunami-container
image: kafkesc/ksunami:latest
args: [
"--brokers", "B1:9091,B2:9091,...",
"--topic", "MY_ONCE_A_DAY_SPIKE_TOPIC",
"--min-sec", "86310",
"--min", "10",
"--up-sec", "10",
"--up", "spike-in",
"--max-sec", "60",
"--max", "10000",
"--down-sec", "20",
"--down", "spike-out",
]
The Docker image is designed so that all the arguments passed to the docker image,
are passed directly to the internal ksunami binary. So, the exact same
usage instructions apply.
As you would expect, for each release of ksunami there will be a corresponding release of ksunami-docker with a matching docker image tag.
At the time of writing, kafkesc/ksunami:latest is kafkesc/ksunami:v0.1.7.
Unlocking the secrets of the __consumer_offsets Kafka Topic
Unless you decide to track your Consumer Offset outside of Kafka, you are likely using the default mechanisms to commit your offsets back to Kafka itself.
Kafka uses a special internal topic to store that information:
__consumer_offsets. The documentation about Kafka internal
Consumer Offset Tracking is a bit wanting, but there are plenty of articles
about this topic.
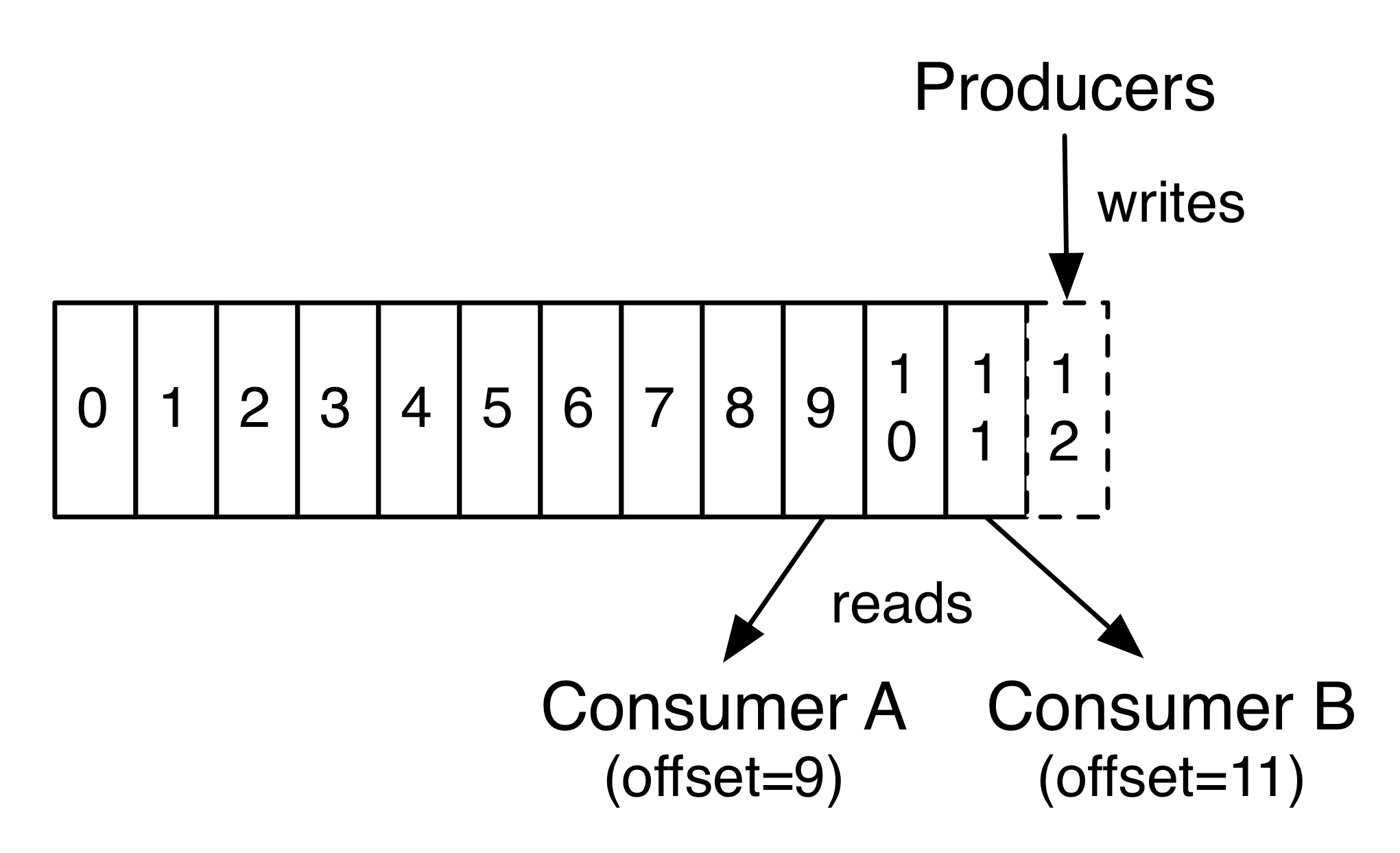
For Kafkesc, where I’m writing everything in Rust in the spirit of learning by doing, I needed a parser for the records that are in this topic. The records keys and values are an entirely bespoke binary format, designed for this very narrow and specific need of tracking Consumer Offsets: nothing generic would do.
I couldn’t find anything in Rust that was able to parse every record and every fields in it, so I built one: kafkesc/konsumer_offsets.
It has the following features:
- Most complete parser for
__consumer_offsetsmessages out there - Reverse-engineering of Kafka 3.x parsing logic, making it retro-compatible by default
- Able to parse the subscription and assignment data contained in
GroupMetadatamessages: beyond what even the Kafka own parser can do - Every struct and field is well documented
- Internal parsing functions are also documented and have references to the code they are based upon: if you read the code, you can go correlate to the Kafka codebase that its imitating
- Parsing is based on bytes_parser (more on this in a sec) and errors on thiserror, so it’s easy to read and handles result errors idiomatically
If you need to consume the __consumer_offsets Kafka Topic, and are looking
for a solid Rust parser,
konsumer_offsets v0.1.1 is on
crates.io. Give it a whirl.
Easiest byte parsing you can find in Rust
When I was reverse engineering Kafka internal logic to implement
kafkesc/konsumer_offsets, I was looking for the Rust equivalent of
Java ByteBuffer: I was looking for a simple wrapper to place around the
raw bytes, and use a plain English interface that would:
- read the correct amount of bytes that encode a specific type
- parse those bytes into that type, and return it
- move an internal cursor, that would move forward the same amount of bytes we had just read
Initially I didn’t find a crate that would do it for me, so I started
writing basic functions parse_<type>() into the
konsumer_offsets project
I was working on.
After a few parsing functions, I realised that a simple yet effective generalization was possible, and that would give me a chance to write my first Rust. So I did.
That lead to creating bytes_parser, currently at version
v0.1.4 on crates.io.
But… what about nom?
I later learned that I could have used nom, but I still think it would have felt like shooting a fly with a cannon, so I’m glad I went my own way.
While nom seems like an excellent and feature reach crate, I needed a simple
wrapper like what I described above. This is also because the work required
was to reverse-engineer the Kafka source code (Scala): in there the logic is
based on types very similar to Java ByteBuffer.
I saw no reason not to put together a super-simple solution, to call my own.
The power of learning by doing
This quick blogpost is a way to crystallize how important is for people like me, to have an active-part in learning: reading a documentation and trying to retain information for later use, just doesn’t work.
At university it was the same: the Computer Science classes that I have absorbed best, are the one that had big laboratory assignment, where you would put to use the concepts.
I know, maybe I’m (like we say in Napoli) discovering hot water here. But I feel very frequently in this industry, that because we are all about efficiency and we hate repeating ourselves, we rely on writing long, information-dense documentations, and then expect people to absorb it.
It doesn’t work for me, and I bet it also doesn’t work for many others.
Things I learned about Rust in the past few months
In the specific, here are a few things about Rust that working on Kafkesc projects lead me to use and pick up (so far):
- How to use Macros to generate source code
- It’s a great idea to have your CI run
cargo clippy - Enums and
matchare the best way to model (exhaustively) multi-branch logic - How to define and implement my own Traits
- Using
ArcandRwLockto make multi-threaded async programming easy - Growing confident with tokio and async/await programming
- Cherish the
Clonetrait - Implement as many common Traits as possible
- Loving the thiserror crate
- Write increasingly better
rustdoc(even for macro-generated function!) - That many Rust projects use dual licensing: Apache 2.0 + MIT
- There is a reason clap is used by everyone, and its declarative syntax is amazing
And probably a lot more that I can’t think of right now.
Conclusion, about Rust
A lot of what I have listed above was already known to me. But by trying to apply business ideas to Rust idioms, trying to model what was in my head, to what Rust wants you to write, is leading to a deeper understanding and learning of this amazing programming language.
And my admiration and respect for it and the people behind it, has grown too.
Conclusion, about Kafkesc
The beauty of not having a deadline, means that I can stop every now and then, and hone something until it looks great, before I move on. Where in a business setting one should never let perfect get in the way of great, with Kafkesc I totally can.
And if a community spawns out of it at some point, that would be a cherry on top. For now, I’m just happy to share my Kafka-centric solutions, written in Rust.
People that have worked with me, likely know or can figure out where I’m heading with this organization: for now, I’ll keep the overarching plan to myself.
]]>